코드 커밋 변경파일 단계별 기록: Commits · taeung515/spring-plus
GitHub - taeung515/spring-plus: spring-plus
spring-plus. Contribute to taeung515/spring-plus development by creating an account on GitHub.
github.com
이번 글에선 코드 리팩토링을 진행하며 생각했던 것들과 배운 것들을 기록하며 공부하고자 합니다. 목차는 다음과 같습니다.
목차
ToMany 페이징 서치
요구사항 QueryDSL을 사용하여 검색기능 만들기

과제를 구현하던 중 드는 생각이 있었습니다. "어? ToMany 관계에서 페이징 처리? 카테시안 곱으로 데이터 수가 many 쪽에 맞춰지면서 페이징 시 limit를 걸면 원하는 결과가 나오려나?"라는 의구심을 품고 일단 구현하기 시작했습니다.
cf) 카테시안 곱이란 두 테이블 간의 가능한 모든 행 조합을 반환하는 연산을 의미합니다. 예를 들어, 하나의 Todo에 담당자 2명과 댓글 5개가 있다면 이론적으로 2 × 5 = 10개의 row가 생성됩니다. 여기서 LIMIT 3을 걸면 실제 원하는 일정 데이터 3개가 아닌 조인 결과에서 단지 3개의 행만 반환하게 되므로 원하는 결과를 얻을 수 없습니다
과제에서의 경험
다음은 엔티티 구성 예시입니다. Todo 엔티티가 managers와 comments를 각각 @OneToMany 양방향 연관관계로 갖고 있습니다

예를 들어, 일정 7번에 담당자가 2명이고 댓글이 5개가 있다면 조인된 전체 row 개수는 총 10개가 됩니다.
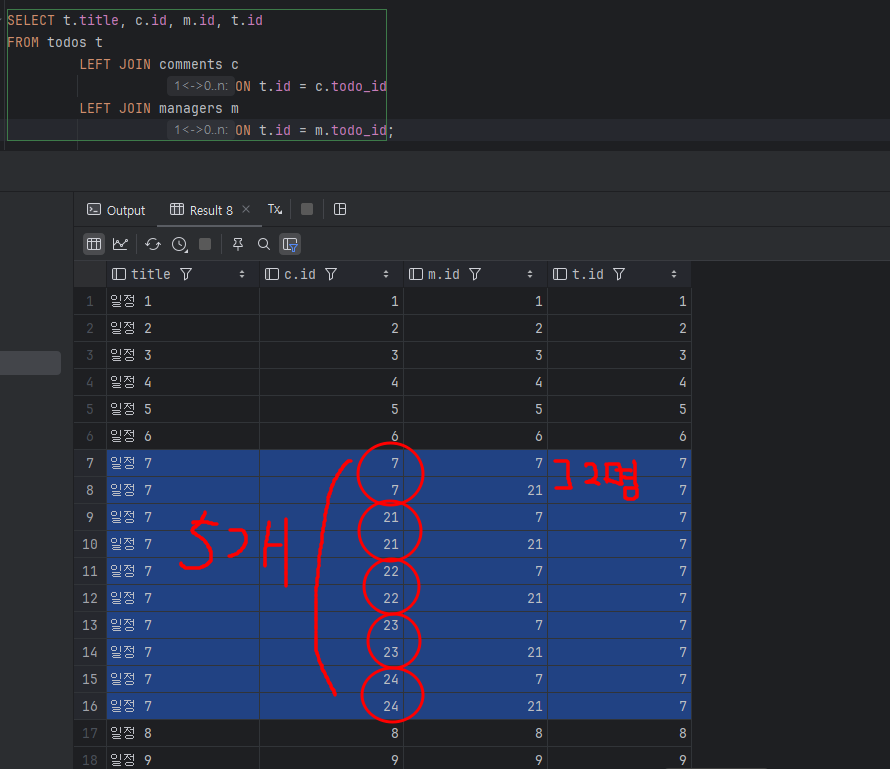
만약 이 상태에서 LIMIT를 걸게 된다면 원하는 일정 데이터가 제대로 나오지 않게 됩니다. 그렇다면 이러한 이론적인 문제가 실제 과제에서도 나타났을까요?
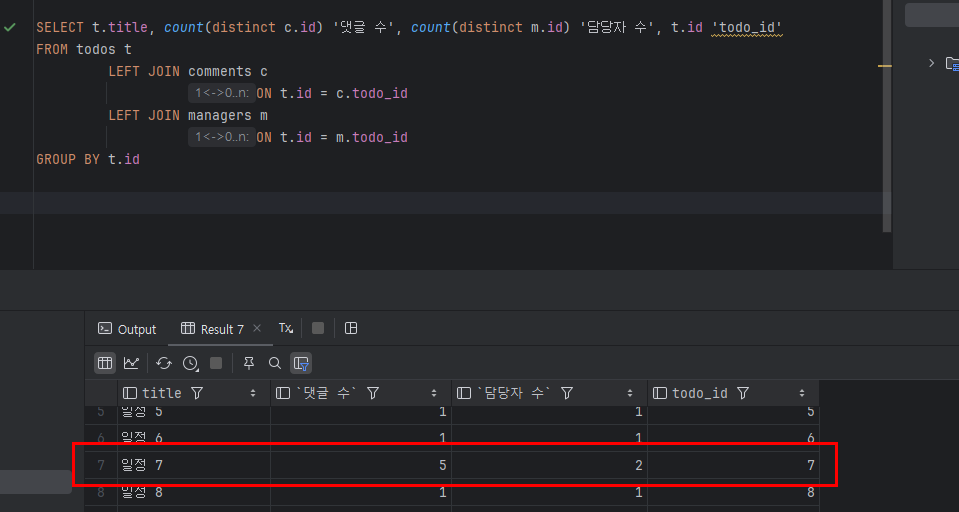
실제로 과제를 구현하는 과정에서는 그룹바이를 통해 중복 데이터를 제거하고 카운트 연산을 수행하였기 때문에 row가 한 줄로 압축되어 LIMIT을 걸더라도 문제가 발생하지 않았습니다.
근본적 문제로 돌아가기
JPA는 기본적으로 단방향 연관관계를 지향하며, 성능상 필요할 경우에만 양방향 연관관계를 구성하라고 권장하고 있습니다. 이 원칙에 따르면 ToMany 관계에서 페이징 처리를 수행하는 것은 신경쓸것이 많아져 적절하지 않을 수 있으며 실수할 수 있습니다, 이 문제는 설계 단계에서부터 신중하게 고려해야 하는 사항이 됩니다.
유저생성 속도 개선
요구사항:

100만명의 유저 더미 생성
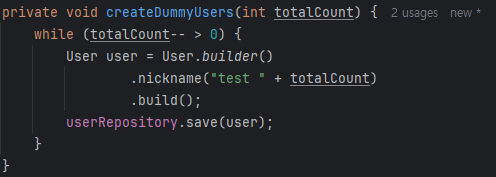
save() vs saveAll()
100만 명의 유저 더미 데이터를 생성할 때 save()와 saveAll()을 사용할 경우 성능 차이가 발생합니다. 이 차이의 원인을 이해하기 위해서는 먼저 두 메서드의 내부 동작 방식을 살펴볼 필요가 있습니다.
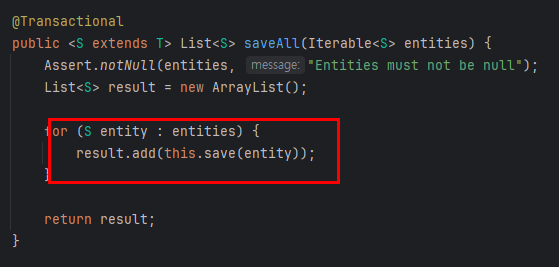
<saveAll 내부>
<save 내부>
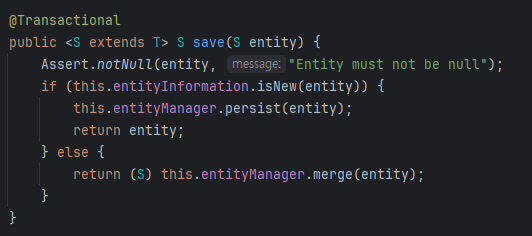
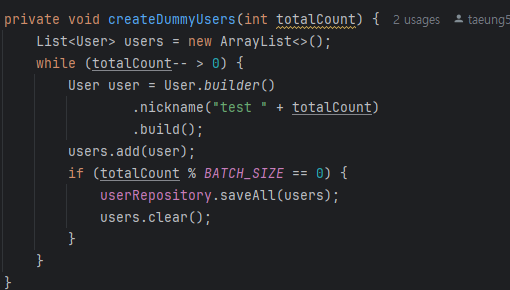
Spring Data JPA의 saveAll()은 내부적으로 루프를 돌며 각각의 엔티티에 대해 this.save(entity)를 호출합니다. 그렇다면 의문이 생깁니다.
“어? 어차피 for문 돌면서 .save()를 호출하는 거면 saveAll()이나 직접 .save()를 루프에서 호출하는 거나 호출 횟수는 똑같지 않나? 그런데 왜 성능 차이가 나지?”
Spring의 @Transactional과 같은 어노테이션은 AOP 기반으로 동작하며, 실제 기능이 적용되기 위해서는 프록시 객체를 통해 메서드가 호출되어야 합니다. 그런데 saveAll() 내부에서 this.save(entity)처럼 자기 자신의 메서드를 직접 호출하면, 이는 프록시를 우회한 self-invocation이 되어 AOP 기능이 적용되지 않습니다. 반면 외부에서 save()를 반복 호출하면, 프록시 객체가 매번 초기화되고, 매 호출마다 트랜잭션이 적용됩니다. 이는 매 요청마다 부가적인 프록시 초기화, 트랜잭션 생성, 커넥션 확보 등의 오버헤드가 생긴다는 뜻입니다.
단일 트랜잭션 범위 안에서 처리
vs
호출마다 프록시가 개입하고 트랜잭션이 반복적으로 생성
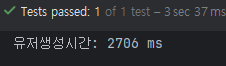
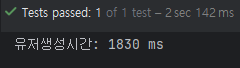
이러한 이유로 대량의 데이터를 저장할 때는 saveAll()을 사용하는 것이 성능 측면에서 훨씬 효율적이며 실제 프로젝트에서도 유저 더미 데이터를 빠르게 생성하기 위해 saveAll()을 적용하게 되었습니다

조회속도 개선


자동 생성된 DQL은 다음과 같았습니다.
SELECT
id, created_at, email, modified_at, nickname, password, user_role
FROM
users
WHERE
nickname = ?;
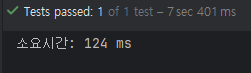

초기 요구사항에서는 nickname 필드가 중복 허용이었기 때문에 우리는 List<User>를 반환하는 쿼리 자동 생성 메서드인 findUserByNickname()을 작성했습니다. 이후 해당 쿼리의 성능을 테스트해 보기 위해 DB 인덱스 유무를 비교, 인덱스를 추가한 후 성능이 124ms -> 67ms로 개선되는 것을 확인할 수 있었습니다.
QueryDSL을 사용하는 이유와 @QueryProjection feat.타입안정성
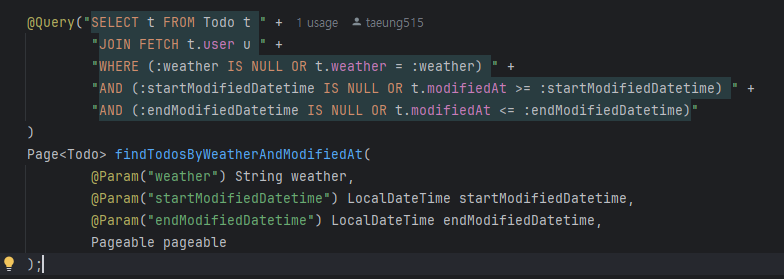
QueryDSL을 사용하는 이유는 조건문 재사용, 휴먼 에러(공백, 오타) 방지, 그리고 타입 안정성입니다.
이 중에서도 가장 핵심적인 이유는 컴파일 시점에 오류를 잡아주는 타입 안정성이라고 생각합니다. JPQL이나 @Query 방식에서는 문자열 기반으로 쿼리를 작성하기 때문에, 오타나 필드 변경 시 오류가 런타임에나 드러나지만, QueryDSL은 정적 타입 기반으로 작성되기 때문에 컴파일 타임에 오류를 확인할 수 있습니다.
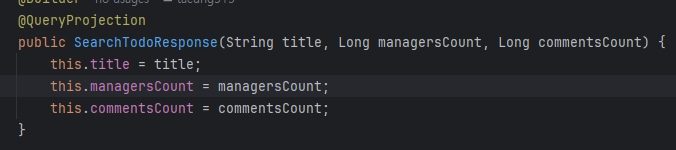
이러한 타입 안정성을 DTO 변환 과정에서도 유지하기 위해, 단순히 Projections.constructor()를 사용하는 대신 DTO의 생성자에 @QueryProjection을 명시하였습니다.
Projections.constructor() 방식은 런타임에 타입 오류가 발생할 수 있지만, @QueryProjection을 사용할 경우 잘못된 타입, 파라미터 순서, 누락 등을 컴파일 시점에 IDE가 경고해주기 때문에 더욱 안전하게 코드를 작성할 수 있습니다.
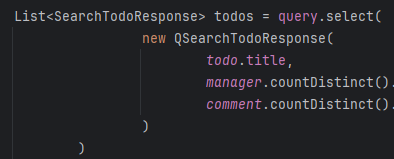
이처럼 부분에서도 쿼리DSL의 사용이유에 맞게 타입 안정성을 최대한 확보하려고 노력하였습니다.
'프로젝트 회고' 카테고리의 다른 글
| 캐시 사용전략 : 왜 Redis인가? 캐시 설계부터 동기화 (2) | 2025.08.24 |
|---|---|
| 아웃소싱 팀 프로젝트 회고: Docker로 프론트 연동 (0) | 2025.06.23 |
| JWT 인증 기반 뉴스피드 프로젝트: 회고 (1) | 2025.06.05 |
| JPA Schedule 프로젝트: 구현 중 발생한 트러블슈팅 (0) | 2025.05.23 |
| JPA Schedule 프로젝트: 유지보수성과 학습을 위한 단계별 구현과정 (0) | 2025.05.23 |


